
I’d like to introduce something that I’ve been excited to start development for some time now, it’s a big project so I’ve been working on various components but this is the first component to be completed.
As a hotelier witness a lot of conversations regarding Airbnb and what I notice most is that nobody has a complete understanding of the impact that Airbnb has on the hotel market. If you believe some articles it is destroying the industry, and in the other extreme if you believe Airbnb has little impact on the hotel industry and may even increase demand due to more domestic travellers able to travel while listing their homes.
I generally choose not to make a definitive judgement because of the lack of true data. However, rather than accepting this as the status quo I have decided to begin building a tool that will help myself and others measure the impact of Airbnb on their neighborhood. There are a few tools out there but many with a high price tag to get access, they are mostly tailored towards helping Airbnb owners and the nature of the data is not as useful to a hotelier who wants to measure the impact that these listings have had on the overall performance of the hotel industry.
There are several complications that need to be accounted for; among them is the fact that there are arguably irrelevant properties in the total numbers (shared rooms, campsites and even boats). To complicate matters there are now a number of hotels listing on Airbnb so these need to be separated. Probably the biggest issue is the way people use the platform, many people list their property for a whole year and may only take a booking for a long weekend when they themselves decide to go away, and others will list it and then remove it from the platform so you have to be able to make an educated estimate as to if the listing has been booked or if it has been removed by the host. This is part 1 of a large number of steps which deals with the initial exploration and collection of some high-level data that will be dealt with later in the processing stage.
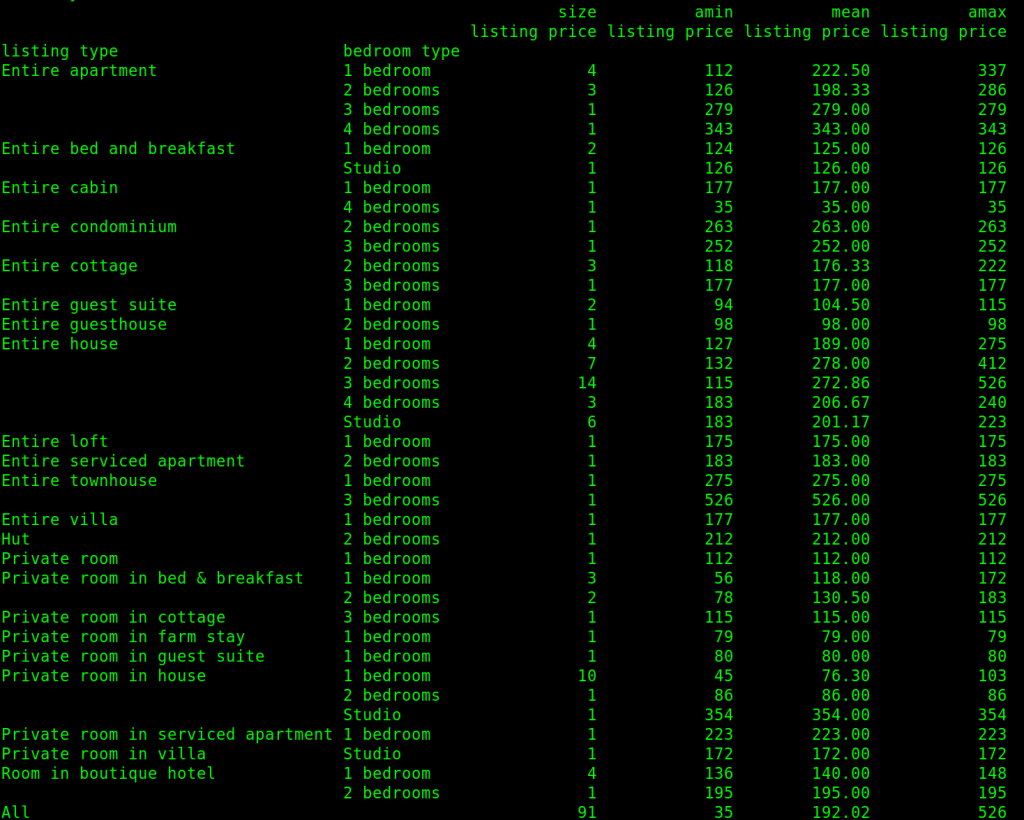
This is a sample of a report that the below program can generate for a search of the town of Sale in Victoria.
So let’s step into a bit of code where we will scrape Airbnb using Python;
First, we’re going to use a number of libraries for this, we will be using Selenium and Beautiful Soup (BS4) for the web enquiries and reading of the HTML from the website, and we will be using Pandas and Numpy for processing the data and a few other libraries for the rest of the logistics.
from selenium.webdriver.chrome.options import Options
from datetime import datetime, timedelta
from selenium import webdriver
from random import uniform
import pandas as pd
import numpy as np
import pyprind
import time
import bs4
import csv
import osFirst, we’re going to build all the functions and then we’ll join the dots and process the data for processing.
We’re going to need the following inputs from the user; check-in date, check-out date, state and suburb. Later I will be looking at collecting the data in the background in a database and the end user will simply log in and put the period that they want to examine and a report will be generated. This will allow for more data to be provided such as types of properties booked, number of rooms booked, average length of stay booked distribution by day of week as well as average rate. These are all important metrics to hoteliers and will give them the best chance of measuring the impact that Airbnb has had on the performance in their area.
First, we want to take the user’s inputs, and then turn them into a list of URLs that encompass this search.
# Takes search parameters, gets all urls, gets listing details and writes to file
def run_program(check_in_date, check_out_date, suburb, state, output_file_name, report_file_name):
cols = ['listing id string', 'listing id', 'listing price', 'listing type', 'no guests', 'bedroom type', 'no beds', 'bathroom type']
url_list = get_url_list(check_in_date, check_out_date, suburb, state) # gets initial list of urls to search by price increments
url_list = get_url_offsets(url_list) # retrieves number of pages for each search - appends these to the list
print(str(len(url_list)) + ' urls in search') # returns number of urls that are in the list to console
bar_total = len(url_list)
# creates progress bar to track progress of program
progressBar = pyprind.ProgBar(bar_total, monitor = True , title = 'Retrieving listing data')
#listing_details = []
write_text_file = open('airbnb_url_list.txt', 'w')
with open(output_file_name, 'w') as f:
write_csv_file = csv.writer(f, dialect = 'excel')
write_csv_file.writerow(cols) # creates labels for the top row the file
for url in url_list:
write_text_file.write(url + '\n')
soup = get_page_html(url)
get_listing_details(soup,write_csv_file)
progressBar.update() # increments progress bar to the next step
write_text_file.close()
print(progressBar)# completes progress bar and prints total time take, CPU and memory usage
write_report(output_file_name, report_file_name)Airbnb limits their searches to 17 pages with 18 listings per page equating to a limit of 306 listings per search which is only a fraction of the listings in many areas. In order to improve the comprehensiveness of the report we will break the search up into $50 increments so that it should capture all listings in all areas. A smaller increment might add to this accuracy however it is important to be respectful of the site that you are scraping and not overload it with enquiries needlessly. This is a courtesy thing understood by web designers and web data collectors but it also reduces your chances of being blocked from the platform which can occur when an unreasonable volume of inquiries is detected by the managers of a website.
For now, i have implemented a function that will instead write any rate search that exceeds 17 pages to a text file so that this can be examined more carefully if desired.
# Airbnb only returns 17 pages of data for each search so this function creates a list
# of urls to search at $50 increments in order to get all listings returned for the given search
def get_url_list(check_in_date, check_out_date, suburb, state):
url_list = []
check_in_date = check_in_date.strftime('%Y-%m-%d')
check_out_date = check_out_date.strftime('%Y-%m-%d')
# starts with a search starting at $10, incrementing at $50 increments until it reaches a starting rate of $990
# any maximum price value over $1000 is treated as infinity
for i in range(10, 990, 50):
min_price = str(i)
max_price = str(i + 50) # makes max price $50 higher than minimum price in search
url = ('https://www.airbnb.com.au/s/homes?refinement_paths%%5B%%5D=%%2Fhomes&checkin=%s&checkout=%s&adults=0&children=0&infants=0&toddlers=0&query=%s%%2C%%20%s&price_max=%s&price_min=%s&allow_override%%5B%%5D=&s_tag=xyPJIRYh'
% (check_in_date, check_out_date, suburb, state, max_price, min_price))
url_list.append(url)
return(url_list)We then want to find out how many pages each price increment contains. This function will do this by iterating through the list of URLs, sending it to the next function that will retrieve the HTML so that we can check the page numbers at the bottom of that search. These will then be appended to the list to capture all bookings.

Airbnb page number section. Capturing these numbers and appending them to the current search URLs will make a full list to be examined.
# Checks each search parameters and finds out how many pages are returned
#for that search and appends these page urls to the current list
def get_url_offsets(url_list):
full_url_list = set()
bar_total = len(url_list)
# starts a progress bar to help keep track of program progress
progressBar = pyprind.ProgBar(bar_total, monitor = True , title = 'Retrieving URL list')
for url in url_list:
soup = get_page_html(url)
page_numbers = []
# saves all page numbers that appear on the page
for i in soup.findAll('div', {'class': '_1bdke5s'}): #page number elements on search landing page
page_numbers.append(int(i.text))
# checks how many page number appear on the page and adds these urls to the list
# if there are none it is assume there is only one page
if len(page_numbers) == 0:
progressBar.update() # updates progress bar to next step
full_url_list.add(url)
continue
else:
pages = max(page_numbers)
# adds all pages to url list
for page_number in range(1, pages):
if page_number == 1:
full_url_list.add(url)
else:
offset = (page_number-1) * 18
full_url_list.add(url+'&items_offset='+str(offset))
if pages == 17:
# if there are 17 pages in the search it writes a record of this in case user wishes to check these searches in more detail
writefile = open('airbnb_17_pages.txt', 'a')
writefile.write(url)
writefile.close()
progressBar.update() # updates progress bar to next step
print(progressBar) # completes progress bar and prints total time take, CPU and memory usage
return full_url_listThis will use selenium which will open a browser in the background and search the URL in question allowing Beautiful Soup to take a copy of the HTML and pass that back to the calling function for processing.
# Scans retrieves html code and returns full code for processing
def get_page_html(url):
chrome_options = Options()
chrome_options.add_argument('--headless') # runs browswer window in the background so as to not interupt user experience
chrome_options.add_argument('--window-size=1920x1080')
chrome_driver = "/usr/lib/chromium-browser/chromedriver"
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path=chrome_driver)
driver.get(url) #navigate to the page
html = driver.page_source
soup = bs4.BeautifulSoup(html, 'html.parser') # saves html to beautiful soup for further processing
time.sleep(uniform(0.5,1.9)) # delay a random time between 0.5 to 1.9 seconds after each search to avoid overloading the website
driver.close() # close browser before moving on
return soupUnlike a lot of HTML, Airbnb uses ambiguous codes to label the elements on their page, for example, the frame that surrounds each listing is called “_gigle7”, so if we retrieve the code within that, it will encompass all the elements within the listing itself. So we cycle through each occurrence of this code and then retrieve our desired pieces of data which is relatively straightforward.
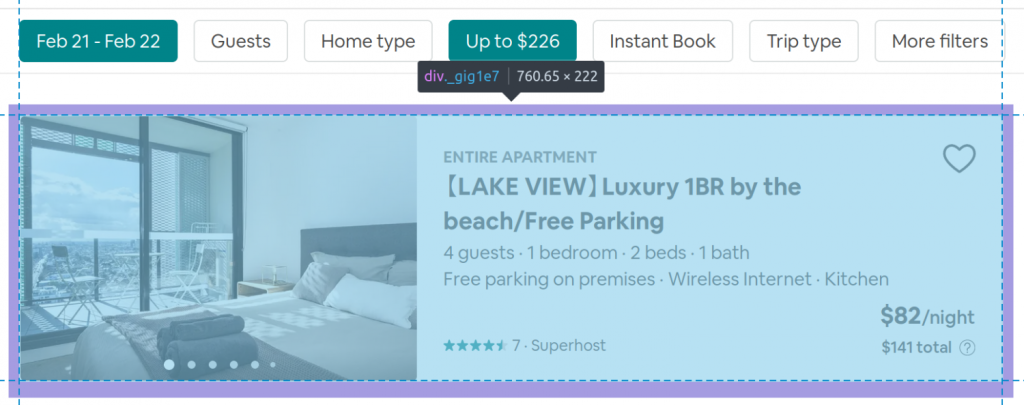
I’ve decided to write each iteration to a spreadsheet one line at a time. This could be handled by storing the data in a data frame or even simply a list of lists. however, while bench-testing this on some systems and a large volume of listings I found that this sometimes caused the program to lag due to the volume of data being stored. This has the added advantage of allowing manual analysis of the data if desired.
# Takes the html for the page, iterates through each listing and retrieves each desired detail
def get_listing_details(soup, write_csv_file):
for listing in soup.findAll('div', {'class': '_gig1e7'}): #frame around each listing
listing_details = [] # new list created for each listing
listing_details.append(get_listing_id(listing))
listing_details.append(get_listing_id_string(listing))
listing_details.append(get_listing_price(listing))
listing_details.append(get_listing_type(listing))
for i in get_listing_bedroom_type(listing).split(' · '): # in for loop because 3 pieces of data are in the same string
listing_details.append(i)
# list as a new row to output csv
# wrote this one row at a time to avoid creating large DataFrame
# in order to not slow down processing on some computers
write_csv_file.writerow(listing_details) Each listing in Airbnb has a unique listing ID, this is called the “target” in their script, this will find that listing id and send it back to the list.
In case it is easier to process for whatever analysis is required at a later date this converts the string with “listing_######”, this extracts the number portion only.
# Converts listing id to numbers only for processing in this form
def get_listing_id_string(listing):
listing_id = listing.find('a')['target'] # unique identifyer for each listing on Airbnb
listing_id_string = listing_id.strip('listing_')
return listing_id_stringBecause in future the web designers may decide to put a border around more than just listings, we’re going to wrap the function of finding the price in a for loop, that way if a total price is not found it is disregarded from the list of properties.
# Retrieve price for listing
def get_listing_price(listing):
try:
price_string = listing.find('span', {'class': '_b4b0hj1'}).text # total price for search
price_integer = int(''.join(list(filter(str.isdigit, str(price_string)))))
return(price_integer)
except AttributeError:
print('get_listing_price error')
passAt the top of the listing, it contains what kind of listing it is, for example, a room in a house or an entire house. I feel it is important to measure like for like and having this information helps to do this.
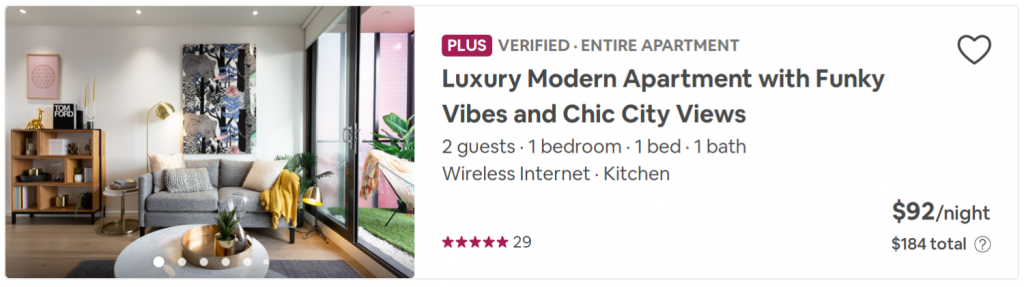
One hiccup is that they also use the same name for the string that identifies the property as a “Plus” property or a “Rare Find”, so we have to eliminate these as they don’t add any value to our analysis.
# Retrieve string at top of listing that descibes if it is an entire premises or shared room ect
def get_listing_type(listing):
try:
for listing_type in listing.findAll('span', {'class': '_1bb2ucx1'}): # string at top of listing descibing listing
# these strings are also tagged with the same identifier to the
# desired string so we want to skip these to get the desired data
if not str(listing_type.string) == "None" and not listing_type.string == "Plus" and not listing_type.string == "RARE FIND":
return(listing_type.string)
except AttributeError:
print('get_listing_type error')
passWe next want to know how many bedrooms are in the property, once again to compare like for like.
# Retrieves number of bedrooms or studio ect, number of guests and bathrooms
def get_listing_bedroom_type(listing):
try:
bedroom_type = listing.find('div', {'class': '_12kw8n71'}).text #string containing guest numbers, bedroom and bathroom details
if bedroom_type is not None:
return bedroom_type
else:
pass
except AttributeError:
print('get_listing_bedroom_type error')
passNow for the final steps! We have all the data, let’s write it into a report.
We’re going to use pandas to do this relatively easily. First, we read the data from the CSV file, and then we can use the pandas pivot table function to format it how we like. For the purposes of this, we want rows for each listing type, sub categories for each bedroom types/numbers within that listing type. The details we want to know about each of these categories and subcategories will be the number of listings which is called size in pandas, the lowest price, the mean/average price, and the maximum price.
We then round this data to two decimal places before both printing the pivot table to the screen as well as writing a CSV file containing this report.
def write_report(output_file_name, report_file_name):
# Reads output file as a DataFrame for processing
df = pd.read_csv(output_file_name)
# Creates pivot table
display_table = pd.pivot_table(df, index = ['listing type', 'bedroom type'],
values = ['listing price'],
# size is pandas's term for count so this will return the
# number of listings per type, and the minimum, mean and maximum rate of these listings
aggfunc=[np.size, np.min, np.mean, np.max],fill_value=0, margins = True)
# Rounds pivot table to 2 decimal places
display_table = np.round(display_table,2)
# When printing a data that comes close to filling the page width pandas skips some data
# this script prevents this from happening
with pd.option_context('display.max_rows', None, 'display.max_columns', None):
print(display_table)
# Writes table to a new file for user to read in future
display_table.to_csv(report_file_name)This will send requests for search information to the console when the program is started.
# Asks user for parameters for search parameters through console
state = input('Enter state for search: ')
suburb = input('Enter suburb for search: ')
suburb = suburb.replace(' ', '%20')
check_in_date = str(input('Enter check-in date for scrape (yyyy-mm-dd): '))
check_in_date = datetime.strptime(check_in_date, '%Y-%m-%d')
check_out_date = str(input('Enter check-out date for scrape (yyyy-mm-dd): '))
check_out_date = datetime.strptime(check_out_date, '%Y-%m-%d')
output_file_name = ('%s/airbnb_output_%s_%s_c-in-%s_c-out-%s_generated_%s.xlsx'
% (cwd, state, suburb,check_in_date, check_out_date, now.strftime('%Y_%m_%d_%H:%M:%s')))
# Creates file name for report file
report_file_name = ('%s/airbnb_report_%s_%s_c-in-%s_c-out-%s_generated_%s.xlsx'
% (cwd, state, suburb,check_in_date, check_out_date, now.strftime('%Y_%m_%d_%H:%M:%s')))This goes down the bottom of the program to take the user parameters and pass them to the ‘run_program’ function to start the ball rolling.
Once run this is what can be generated for a day in April in the town of Sale, Victoria.
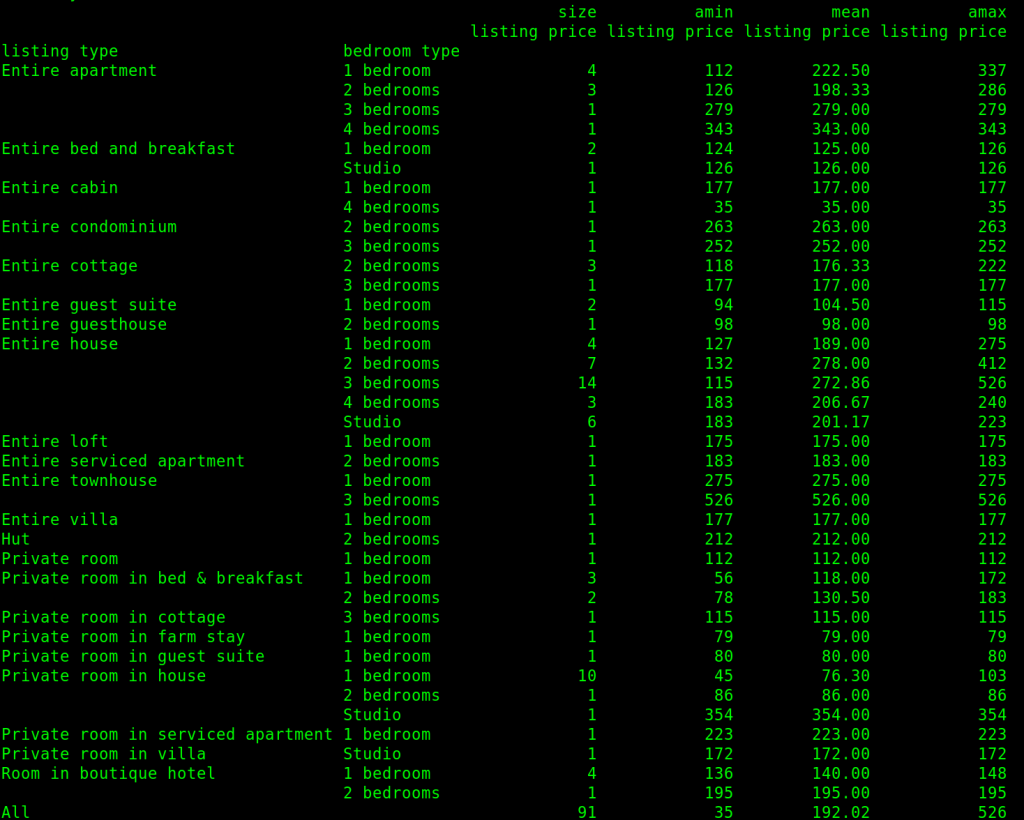
It has also been sent to CSV files with both the raw data and the report.
Leave a Reply